 |
 |
 |
| LCS&E Collaborative Research Activities Over the vBNS |
Intended LCS&E research uses of the vBNS connectivity to be established include:
The three uses of the proposed high performance networking are discussed in
the context of specific projects below.
Distributed Computing
We have developed special versions of our PPM gas dynamics code which can be
used to carry out a single, tightly-coupled, hydrodynamics simulation using
clusters of shared memory multiprocessors (SMPs) on a high performance
network. The manner in which the shared memory multitasking on each SMP is
performed makes possible a very aggressive overlapping of computation and
communication so that very large network latencies can be tolerated. These
codes are early examples of a new genre of applications which we call latency
tolerant applications. The programming techniques involved, which rely upon
the shared memory programming paradigm at each netork node, offer the
potential to unite geographically dispersed supercomputer resources on a high
performance network in order to assemble metacomputing systems of
unprecedented capability.
We will experiment with using both 2-D and 3-D versions of PPM to combine SMPs at the Laboratory for Computational Science & Engineering (LCS&E) at the University of Minnesota with SMPs at NCSA in Illinois. We intend to restrict our early experimentation to SMPs from Silicon Graphics, on which our initial latency tolerant programs have been developed, but SMPs from other vendors could be connected into single computing resources in this way later in the course of the project. Working with the I-WAY team, we would like to include Silicon Graphics SMPs at the Army Research Laboratory in Aberdeen, Maryland, to those at the LCS&E and NCSA to demonstrate greater aggregate power assembled over greater geographical distance. Silicon Graphics SMPs at the Cornell Supercomputer Center or at another site connected to the vBNS could also be included.
|
|
|
|
The key to our latency tolerant implementations of our PPM code is to decompose the entire problem domain into tiles in 2-D or bricks in 3-D, with one large tile or brick resident on each network node (SMP). The shared memory programming paradigm, supported in hardware on the SMP, is then exploited to decompose this subdomain still further into chunks which are processed in a special order. These chunks may themselves be tiles or bricks, but the most effective implementations exploit the shared memory on the SMP to use other shapes, such as strips or pencils of the subdomain grid. These subdomains of the subdomain at a network node are processed as individual tasks assigned to the multiple processors in order. The order of processing is chosen so that the longest messages which must be sent to other network nodes may be dispatched as early in the computation as possible. This early message dispatch is a mechanism to tolerate not only large message passing latencies but also low network bandwidths.
The shared memory multitasking performance of our 3-D sPPM gas dynamics code,
as measured on the 12-processor Silicon Graphics Power Challenge machine at
the LCS&E is given in the following table:
| GRID | CPUs | SPEED-UP | Efficiency | Gflop/s |
|---|---|---|---|---|
| 256x256x256 | 1 | 1.00 | 100% | 0.0921 |
| 256x256x256 | 2 | 1.99 | 99.6 | 0.183 |
| 256x256x256 | 4 | 3.95 | 98.7 | 0.364 |
| 256x256x256 | 8 | 7.60 | 95.0 | 0.700 |
| 256x256x256 | 12 | 11.1 | 92.4 | 1.021 |
The example of a 512x256x256 PPM gas dynamics computation just discussed illustrates the principles involved in distributed computing of tightly coupled problems. However, the aggregate computing resource assembled is only 2 Gflop/s. This much computing power is already available at the LCS&E in two Silicon Graphics SMPs. Far greater computing power is presently available at NCSA. Within the two-year scope of this project, we hope to have roughly 4 times the computational power at the LCS&E which is given in the above example, so that roughly 2 MByte/sec of sustained network bandwidth would be required for such cooperative computation. In this case, an aggregate grid of 512x512x512 could be updated in the same time as required for the 512x256x256 grid of the previous example.
There is another important factor to consider here. An important reason to combine computing resources over a network is to get exploratory jobs done very quickly, perhaps even interactively. As we reduce the problem size by a factor of 2 in each dimension, each pencil update takes only half as long, but the message which must be sent over the network during this time remains the same size. Thus, for a computation on a 256x256x256 grid, which would take 8 times less time per mesh update as the previous example of a 512x512x512 grid, a sustained network bandwidth of 8 MByte/sec would be required. A vBNS connection between the LCS&E at the University of Minnesota and NCSA at ATM OC-3 bandwidth would meet this requirement, even if only half of this bandwidth were available for high performance networking research experiments.
It should be noted that the problem sizes discussed here are not unreasonably large. The largest PPM computation to date was performed in September of 1993 on an experimental Silicon Graphics computing system consisting of 16 Challenge XL machines with 20 processors each. These machines were interconnected on 20 FDDI rings, and the PPM code implementation used in that experiment could tolerate message passing latencies of seconds for the 1024x1024x1024 grid used in that computation.
In addition to the research to be carried out involving the restructuring of
large-scale simulation codes to accommodate latency tolerant distributed
computing, we plan to experiment with HiPPI tunneling over the proposed ATM vBNS
connection. HiPPI tunneling could make possible more transparent use of the
combined array of resources at the LCS&E and at NCSA, where each local network
is based on HiPPI. This project also will involve issues of coordinated
resource scheduling at the LCS&E and at NCSA. We plan to address this issue
initially by arranging for special periods of dedicated resource allocation,
but if this distributed computing paradigm is to be widely used, more automatic
means of performing such resource scheduling would be desirable. We will make
a modest start, coordinating resources at only two distant locations, but
ultimately an automatic scheduling mechanism which has some of the functionality of a network operating system would be desirable. We note that dynamic
allocation of network bandwidth as well as of computing resources on the
network is the goal. We hope that our experimentation will give us some
valuable experience from which the critical issues and procedures for such
an automatic system might be distilled.
Visual Supercomputing
Visual supercomputing is a term intended to represent the integration of high
performance computing and scientific visualization. One manifestation of this
integration is the visualization of an ongoing supercomputer simulation as it
happens, perhaps with the added capability to alter the course of this
computation in useful ways. Because of the expense of the necessary hardware,
the most common use of visual supercomputing is expected to consist of a user
with a graphics workstation connected over a high performance network to a
supercomputer (which may itself be a distributed system).
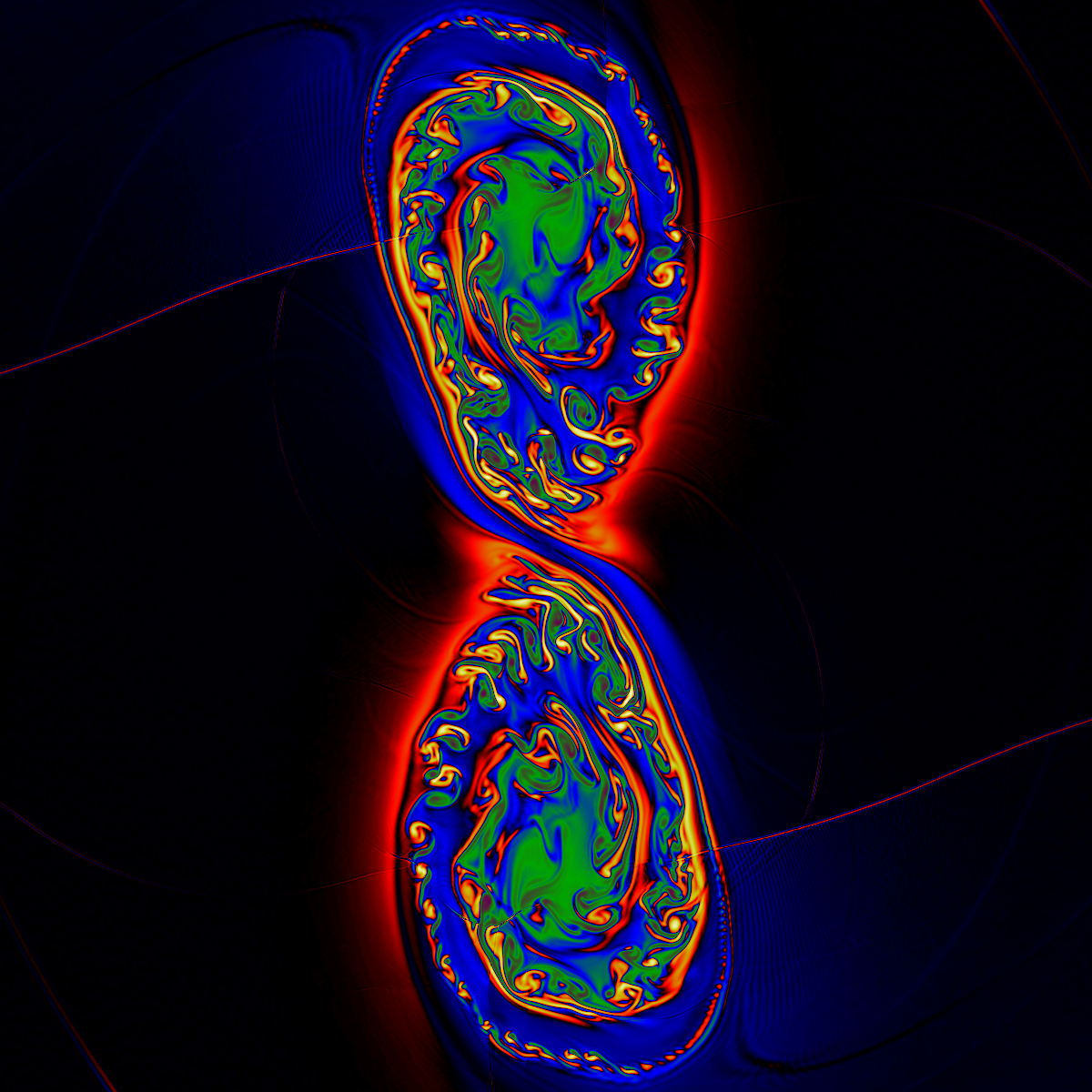
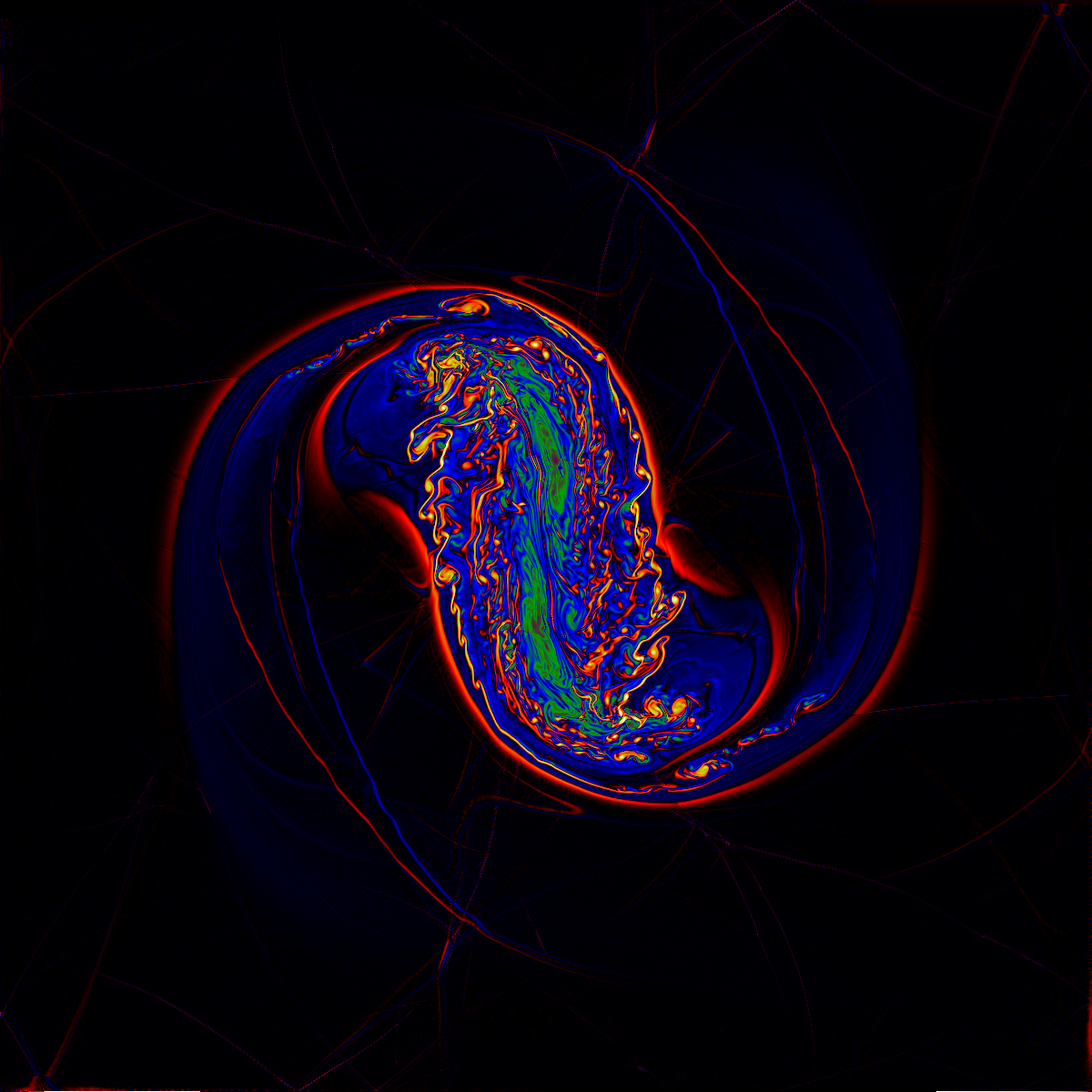
Let us take the example of the 256x256x256 PPM gas dynamics simulation discussed above. Suppose that the computation itself is carried out at NCSA using 8 SMPs, each updating a 128x128x128 subgrid at 1 Gflop/s. Each mesh update would require about 2.5 sec for this problem. Suppose that the researcher located at the LCS&E were to specify, as the computation proceeded, a particular variable, such as the magnitude of the vorticity, which he or she wanted to visualize. Then one would want to receive over the network a "brick of bytes" representing this variable about every 10 mesh updates, or every 25 seconds. Such a brick of bytes would contain a single byte representing a scaled vorticity magnitude at each of the 16.7 million grid cells. Sending this data over the network during the interval required to advance the simulation and construct the next brick of bytes would require a sustained network bandwidth of 655 KByte/sec. If multiple variables were to be sent, so that side-by-side visualizations could be constructed at the LCS&E, then this network bandwidth requirement would have to be multiplied by the number of variables desired. In this scenario, the researcher at the LCS&E would use the considerable computational and graphics rendering power of the LCS&E's PowerWall visualization system to explore the evolving flow field interactively. With the dual "Infinite Reality" engines on the SGI Onyx machine driving the PowerWall at the LCS&E, we expect that volume renderings of the 256x256x256 bricks of bytes could be generated at a rate of a few per second, permitting a virtual tour through the evolving flow. In this case, the flow field would be updated every 25 seconds. More frequent updates could also be performed, with correspondingly higher network bandwidth requirements.
|
The above example assumes that 8 Gflop/s of computing power would be dedicated to this computation on the NCSA cluster of Silicon Graphics machines. Within the two-year extent of this project, we expect that NCSA will obtain equipment capable of delivering at least 4 times this processing power to a single application like PPM. The sustained network bandwidth needed for the 256x256x256 PPM gas dynamics problem, with a single fresh brick of bytes delivered to the LCS&E every 10 time steps, or every 8 seconds, would then be over 2 MByte/sec. It should be noted that this network bandwidth would need to be sustained for the life of the computer simulation, which, at this grid resolution, is likely to range around 2 hours for a run covering about 16 characteristic dynamical times, or 8000 time steps (typical of the PPM runs in our NSF Grand Challenge program to date).
The computation described above would represent a substantial commitment of
computing resources. It is therefore unlikely that only the particular
variable and scaling function requested for the interactive visual exploration
of the evolving flow field would be needed after the run was completed in
order fully to understand the run's scientific significance. Consequently,
complete information about the flow, with two bytes per variable per grid
cell, would be saved on disk at NCSA during the run. This data is, for 6 flow
variables, 12 times more voluminous than that sent over the network to the
LCS&E during the run. At the same network bandwidth required for the
interactive visualization during the two hours of this run, all this data
could be sent over the network to the LCS&E in 24 hours. This data would
consist of 800 data dumps of 192 MByte each, for a total data set size of
150 GByte. This data could easily be archived on a single Ampex D-2 tape
cartridge, from which it could be extracted at any later time at 14 MByte/sec
sustained bandwidth. (Ampex D-2 tape drives are presently used at NCSA and
at the LCS&E.) Equivalently, the complete data from the 2-hour run could
be archived on D-2 tape at NCSA and mailed to the LCS&E, arriving in the
same time, namely 24 hours. The archiving rate required to keep up with
the data from this run would be 24 MByte/sec, or the combined throughput
of two D-2 tape drives.
Collaborative Scientific Visualization
Collaborative scientific visualization involves researchers at geographically
separated sites using a high performance network to carry out a simultaneous
visualization of a data set which is either stored at one site, at both sites,
or, in the most demanding situation, at a third site. The visualization
engines at these sites could simply be high performance graphics workstations,
like those of our Grand Challenge team collaborators at the University of
Colorado, or they could be special visualization systems, like the
PowerWall
at the LCS&E or the CAVE at NCSA or the Electronic Visualization Laboratory
(EVL) in Chicago. PowerWall systems are being installed at both the EVL and
at NCSA which could be connected to the PowerWall at the LCS&E for
collaborative scientific visualization as well. Visualization systems of
very high
resolution, like the 7.6 million pixel PowerWall or the CAVE, make the
greatest demands upon network bandwidth. Since these systems each have
considerable graphics rendering power, the network can be used to send raw
data rather than images between the distant sites. In this case, the
bandwidth requirements are essentially the same as those listed in the
previous section for the visual supercomputing example. A possible difference
from that example is that the data in question might merely be extracted from
some online data archive rather than be fed by an ongoing supercomputer
simulation.

|
Particularly if both researchers at the geographically separated sites wish to see not only the same data but also the same view of that data, one site (or possibly even a third site) can act as the image server. In this case a steady stream of interactively generated images must be sent over the network to the remote site (the image client). Without hardware supported image compression and decompression, this demands at least 32 MByte/sec sustained network bandwidth. We do not expect such sustained network bandwidth to be provided over interstate distances any time soon. Therefore, either we will need to experiment with hardware image compression and decompression or redefine our concept of interactivity if we wish to consider collaborative visualization via image serving. One mechanism of hardware supported image compression and decompression is presently available to us. The compressed image format, which we might consider sending over the network, is the display list of polygon vertices and attributes which the Silicon Graphics hardware is able to expand into a full image extremely rapidly. A scene to be rendered at 5 million pixel resolution in a CAVE, for example, might be specified by only 120,000 polygon vertices. These polygons could then be used to draw an entire sequence of images. This mode of operation begins to resemble that of sending voxel data over the network at 8 or 25 second intervals, as discussed earlier, and then relying on the special rendering hardware at each remote site to draw the images which allow the collaborative visualization. Once this raw data is at both sites, only viewpoints and view directions need to be communicated between them.
The sort of collaborative scientific visualization described above would greatly enhance the research of our Grand Challenge team which is investigating geophysical and astrophysical turbulence. In addition, researchers on our CISE infrastructure project are visualizing very large data sets from studies of the structure of brains of rats and mice and from digital scans of photographic plates from optical telescopes. Our CISE infrastructure project, which funds the PowerWall at Minnesota as well as some networking activities, specifically addresses research into the use of high performance networks to visualize large data sets stored at remote locations. This research would be enhanced by enabling more distant researchers, such as our Grand Challenge team members in Colorado or collaborators at the EVL and NCSA, to experiment with this form of remote visualization and collaborative visualization. For the brain datasets and the digitized Palomar Sky Survey data just mentioned, we would like to experiment with popular data compression schemes developed for digital video applications. These data sets, taken from observing equipment rather than from computer simulations, do not contain natural compressed representations like the polygon display lists mentioned above. They are therefore candidates for JPEG compression. We would also like to experiment with remote observing of a precomputed digital movie over the vBNS. For this application, either our team or our collaborators at the University of Colorado would generate a movie to aid in the discussion of our joint fluid dynamics research. This movie could then be viewed by the other team over the vBNS. To facilitate this use of the network, we would like to experiment with MPEG-1 and MPEG-2 data compression. It would be particularly useful if our own, freely available digital movie viewing software, XRAZ, could be adapted to reference a movie on a remote machine in another state and display it with all the interactive controls on display speed, zoom factor, forward or backward animation, or jumps to specific frames which we have grown accustomed to use on our local graphics workstations. This sort of application, which could be used by the brain project as well, could be a testbed for developing high performance video information servers for the vBNS.
